بر اساس مطالعه جدید محققان دانشگاه میشیگان، یک روش مهندسی پروتئین با استفاده از آزمایشهای ساده و مقرونبهصرفه، مدلهای لرنینگ ماشین میتوانند پیشبینی کنند که کدام پروتئین برای یک هدف معین مؤثر خواهد بود.
این روش دارای پتانسیل گسترده ای برای جمع آوری پروتئین ها و پپتیدها برای کاربردها از ابزارهای صنعتی گرفته تا درمان است. به عنوان مثال، این تکنیک می تواند به سرعت بخشیدن توسعه پپتیدهای تثبیت شده برای درمان بیماری ها به روش هایی که داروهای فعلی نمی توانند کمک کند، از جمله بهبود نحوه اتصال انحصاری آنتی بادی ها به اهداف خود در ایمونوتراپی کمک کنند.
مارشال کیس، فارغ التحصیل دکتری مهندسی شیمی در دانشگاه UM و اولین نویسنده این مقاله می گوید: “قوانینی که بر نحوه عملکرد پروتئین ها، از توالی تا ساختار عملکرد، نظارت می کنند، بسیار پیچیده هستند. کمک به مطالعه تفسیرپذیری تلاش های مهندسی پروتئین بسیار هیجان انگیز است.” .
در حال حاضر، بیشتر آزمایشهای مهندسی پروتئین از روشهای پیچیده، کار فشرده و ابزارهای گران قیمت برای دستیابی به دادههای بسیار دقیق استفاده میکنند. فرآیند طولانی میزان دادههای قابل دستیابی را محدود میکند، و یادگیری و اجرای روشهای پیچیده چالش برانگیز است
کیس که اکنون یک زیست شناس محاسباتی در Manifold Biotechnologies است، گفت: روش ما نشان داده است که برای بسیاری از کاربردها، می توان از این روش های پیچیده اجتناب کرد.
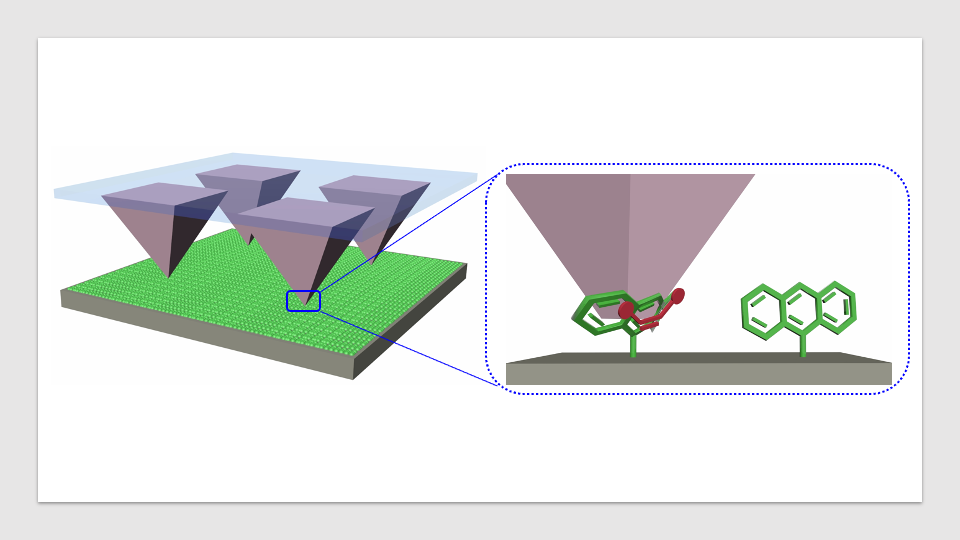
روش به روز شده با مرتبسازی سلولها به دو گروه، معروف به مرتبسازی باینری(بایونری)، بر اساس اینکه آیا آنها یک صفت مورد نظر را بیان میکنند – مانند اتصال به مولکولهای فلورسنت – شروع میشود یا خیر. سپس، سلول ها توالی یابی می شوند تا کدهای DNA زیرین پروتئین های مورد نظر را بدست آورند. سپس الگوریتم های یادگیری ماشینی نویز را در داده های توالی یابی را کاهش می دهند تا بهترین پروتئین ممکن را شناسایی کنند.
گرگ میگوید: «بهجای انتخاب «بهترین کتاب» از کتابخانه، مانند خواندن کتابهای زیادی است، سپس صفحات مختلف داستانهای مختلف را کنار هم میچینیم تا بهترین کتاب ممکن را پیدا کنیم، حتی اگر در کتابخانه اصلی شما نباشد.
دانشیار مهندسی شیمی UM و نویسنده مسئول مقاله گفت: من از دیدن قوی بودن این تکنیک با استفاده از داده های مرتب سازی ساده و باینری شگفت زده شدم.
این روش برای افزایش دسترسی خود، از مدلهای یادگیری ماشین خطی استفاده میکند که در مقایسه با مدلهایی با دهها پارامتر، تفسیر آسانتر است.
کیس گفت: «از آنجایی که میتوانیم قوانین فیزیکی در مورد نحوه عملکرد پروتئینها را بیاموزیم، میتوانیم از معادلات خطی برای مدلسازی رفتار غیرخطی پروتئین و ساخت داروهای بهتر از این طریق استفاده کنیم.»
Materials provided by University of Michigan. Note: Content may be edited for style and length